 Engram: Generative audio samplerFeb 2026Building a sampler with on-device generative audio models.
Engram: Generative audio samplerFeb 2026Building a sampler with on-device generative audio models.
 A private ambient summarizer deviceJan 2025
A private ambient summarizer deviceJan 2025
 Moonshine: Industry-leading edge ASROct 2024I'm a core contributor to the Moonshine ASR models: 5x faster than Whisper with higher accuracy.
Moonshine: Industry-leading edge ASROct 2024I'm a core contributor to the Moonshine ASR models: 5x faster than Whisper with higher accuracy.
 Teaching things to thinkMay 2024Training smart devices to reason about their actions and state; our award-winning IEEE PerCom '25 paper.
Teaching things to thinkMay 2024Training smart devices to reason about their actions and state; our award-winning IEEE PerCom '25 paper.
 Sasha: Introducing LLMs for smart spacesMar 2024I built the first LLM-powered smart home and published the methods, benchmarks, and user study in this ACM IMWUT paper. I was honored to receive an ACM Distinguished Paper Award for this work.
Sasha: Introducing LLMs for smart spacesMar 2024I built the first LLM-powered smart home and published the methods, benchmarks, and user study in this ACM IMWUT paper. I was honored to receive an ACM Distinguished Paper Award for this work.
 Adding eurorack features to a tape recorderDec 2023Adding independent audio outputs and gates to a TASCAM Porta 03 tape recorder.
Adding eurorack features to a tape recorderDec 2023Adding independent audio outputs and gates to a TASCAM Porta 03 tape recorder.
 The Sky Doesn't End at the Top of the PageDec 2023
The Sky Doesn't End at the Top of the PageDec 2023
 CANDor: Energy efficient neighbor discoverySep 2023
CANDor: Energy efficient neighbor discoverySep 2023
 Northern California, Summer 2023May 2023
Northern California, Summer 2023May 2023
 Using LLMs to control a smart homeMar 2023Experimenting with GPT models to build a smarter smart home assistant.
Using LLMs to control a smart homeMar 2023Experimenting with GPT models to build a smarter smart home assistant.
 Self-updating pothos timelapse cameraSep 2022An IoT project that monitors the growth of my pothos plant.
Self-updating pothos timelapse cameraSep 2022An IoT project that monitors the growth of my pothos plant.
 My Plants Are Hanging on by a ThreadJun 2022
My Plants Are Hanging on by a ThreadJun 2022
 Curvature of the EarthDec 2021
Curvature of the EarthDec 2021
 Texas Hill Country, 2021Nov 2021
Texas Hill Country, 2021Nov 2021
 Petri: Cellular rhythm generator for eurorackMar 2019Designing a eurorack module that generates rhythms from cellular automata.
Petri: Cellular rhythm generator for eurorackMar 2019Designing a eurorack module that generates rhythms from cellular automata.
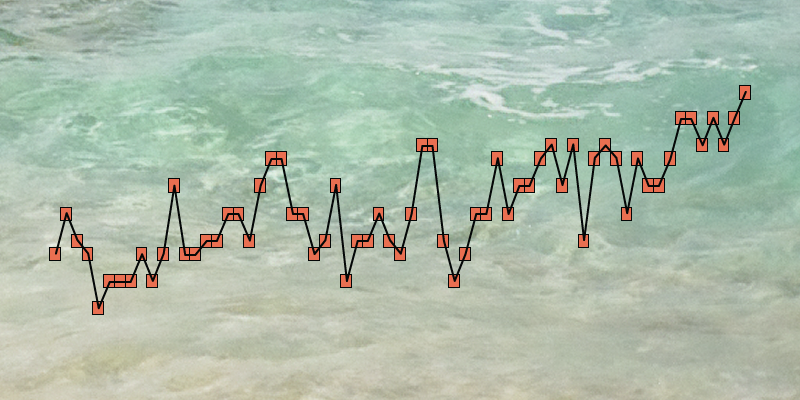 From sea levels to music with CSV to MIDIFeb 2018Building and using my csv-to-midi data sonification tool in a mixed-media art project.
From sea levels to music with CSV to MIDIFeb 2018Building and using my csv-to-midi data sonification tool in a mixed-media art project.
 Okinawa, 2017Jul 2017
Okinawa, 2017Jul 2017
 Reverse-engineering an RFID writerNov 2016Turning an RFID card writer into an active scanner and keyboard wedge.
Reverse-engineering an RFID writerNov 2016Turning an RFID card writer into an active scanner and keyboard wedge.